Searching on the web started by imitating analog, text-based searches. This technique was not cutting the mustard for image search, and search engine developers knew it.

Why? Because people don’t think about images in words. We see things we want, we save pictures, and we recall images with startling clarity in our mind’s eye. Only when forced do we add textual attributes—colors, size, shape, texture—to describe images.
Making image search tech that fits the human model of behavior has involved a long quest focused on providing one thing: giving people the ability to search for images without using words. Today, we finally have working iterations for this idea. You can now search for images with an image, and computers can recognize and categorize images better than ever.
But it’s been a long road from text searches to advanced image recognition, and we’re still developing the technology. But for anyone who wants to understand the history of how one of our most used resources—search—has developed to our specific tastes, stick around.
Text-to-image description: The beginning
In the beginning, to find an image, you would come up with some words to describe what you wanted to see—say, “top of Mount Everest.” Then, you’d type those words into search. The search engine would find a matching image by scanning the text of pages that images were on—image titles, descriptions, and any accompanying text—and return something that appeared to match your search, based on its textual context.
This started in the late ’90s, when AltaVista launched an image feature for its search that allowed you to put in a text term and return images. This was a proximate way to get people to the pictures they desired. Early image searches like AltaVista’s relied not on the ability to process the image itself and match that to text, but on image descriptions or corresponding text on web pages.
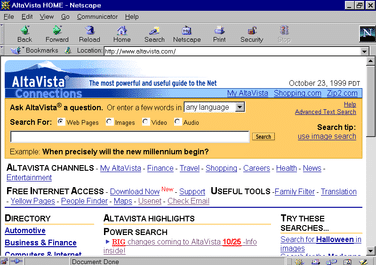 AltaVista search late 1990s (Source)
AltaVista search late 1990s (Source)
Google Images, which followed in 2001, quickly amassed a huge store of pictures—250 million within the year. It was developed because people wanted to get not to approximate images based on the context of web pages but to the exact image that they had in mind. Legend has it that specific queries for Jennifer Lopez’s risqué Versace dress were the catalyst.
 (Source)
(Source)
Even if they weren’t, that idea is right at the heart of how early image search failed users: They wanted a specific picture and had no way to reliably search for it. People transfixed by Lopez’s stunning outfit knew what they were seeing, but they didn’t have the detail—designer, event, celebrity—to match it perfectly with surrounding text. Searching for “green dress” probably produced results like this:

Technically accurate, but not JLo. While early search was still developing—both for text and images—the failures in the methodology didn’t have that much to do with the tech, per se. People could match genres of images to text queries. If you searched “green dress,” you would have gotten green dresses back, because those writing the descriptions were writing accurate descriptions of the contents.
But users had to search by proxy and hope for the best instead of getting an immediate payoff of what they could picture in their mind. They could guess at terms used to describe an image, but the subjectivity of the person querying and of the person writing the descriptions used to index an image made it hard to be exact.
Figuring out the digital image: Recognition advances
The next step in developing a better, more intuitive image search was of CBIR, or content-based image retrieval. CBIR analyzes the contents of the image rather than just scanning for keywords around it. Things like color and shape can be directly connected with an image without the need for any text clarification.
While text-to-image description was being developed, researchers understood that deriving qualities from the image itself, rather than by proxy via text descriptor, would be a better way to search. And although this was developed and researched early to overcome some of the limits of text to digital image, this text-to-image qualities search didn’t take off right away.
It started to help small collections of images but could not immediately be scaled to the magnitude of images that were appearing online—like the 1 billion images indexed by Google and Yahoo! in 2005. Text attributes of an image (file name, image captions, etc.) simply remained easier to work with on a large scale.
Furthermore, the technology for “describing” images wasn’t quite there. Computers could sort through things such as dimension pretty well, but when it came to actually recognizing an image, gray areas started to appear. Images with high contrast in the same areas, for example, might be paired, even though they were images of different things. These factors limited the application of CBIR through the ’00s, with the largest library using CBIR clocking in at only 3 million images.


Images with similar contrast could be hard to distinguish. (Source, Source)
So, while people were able to recognize a problem with the nature of text query to text descriptor search, there wasn’t a viable solution out there just yet.
Reverse and similar image search: A step forward
Then came the most effective form of CBIR to date: “reverse” image search, where the input from the user was not text, but an image itself. This obviously removed a layer of guesswork from search queries, because it didn’t rely on a user to describe the image they were thinking of with text. Instead, they were using the image itself.
TinEye was the first to use image-to-image search, and other engines quickly followed. The use case for reverse image search is limited; the service is designed to match an image with another image to find its source. This is a valuable tool that we still use today, but it didn’t cover all the weaknesses of image search as it stood.
But as more and more accurate indexing of images based on visual attributes grew, search engines started to implement features that clustered similar pictures together in response to searches. Google’s Image Swirl was one such project, and one of the first that the company pulled out of research for consumer purposes. It combined looking for visual cues with meta text elements of photos to allow users to explore similar images, like various angles and night photos of the Washington monument:
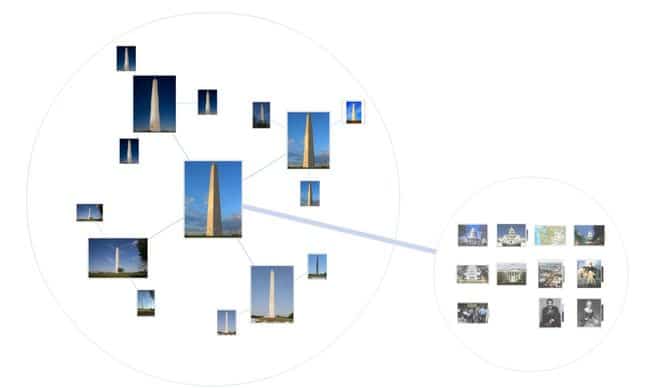 (Source)
(Source)
This was a way for consumers to begin exploring similar content, and the same idea has continued even in regular Google Image search today in the “related images” section:
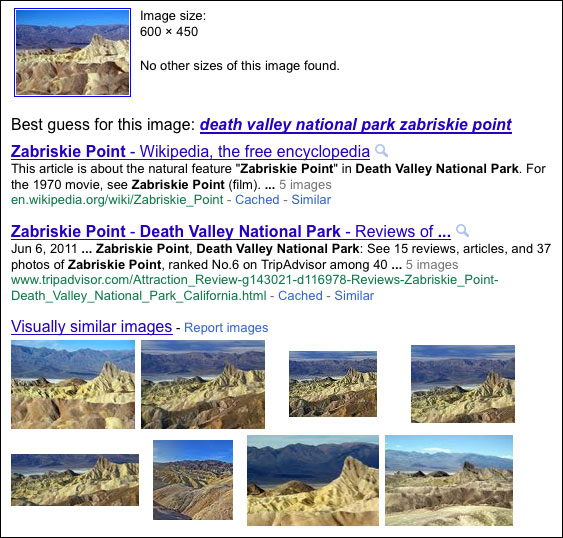 Search by Image, 2011 (Source)
Search by Image, 2011 (Source)
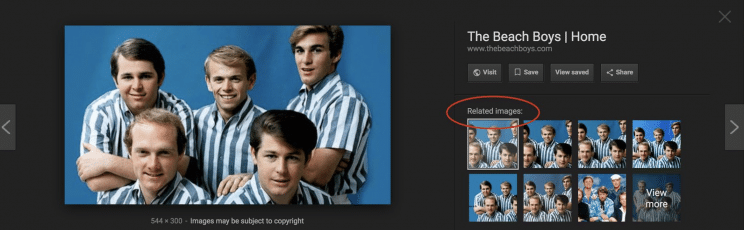 From 2018.
From 2018.
Part of the limitation in the way that this is configured is that you tend to get duplicate images when an image is widespread. It was (and is) also a feature that’s embedded into text to search and doesn’t necessarily provide the intuitive search results of image-to-image search. Luckily, we’ve made some significant advances since this launched in 2010.
Image-to-image search: The final frontier
The common theme throughout every iteration of image search thus far has been that on one or both ends of the search, we’ve been relying on humans writing descriptions of images. Even when search started to get into pairing similar images, it was either limited to finding the source of an image or finding similar images to one that had been searched for with a string of text.
And it was clear that people developing search capacity and image recognition knew this and wanted to solve it with better technology. So they did. Two huge advancements on this front are facial-recognition technologies and image-to-image search.
Facial recognition is pretty intuitive and isn’t necessarily used for search. But it does represent a fine-tuned approach to automated image recognition. We’ve all had the errant inanimate object or pet that’s been mistaken for a human face, but recognition is improving every day. Usually it’s used on social and not in search, but it’s a piece of the puzzle.
 Australian politician or potato? (Source)
Australian politician or potato? (Source)
What’s exciting in terms of search right now is image-to-image search. It’s exactly what it sounds like: A user puts in an image instead of a text string to find similar images, and the search engine returns images with similar qualities to the input image.
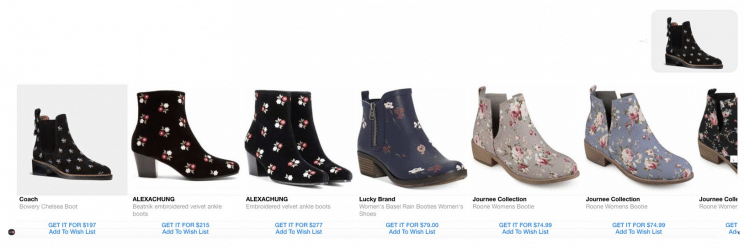
Take this Syte search for an embroidered Chelsea boot. The input is an image, and the search finds not only that exact shoe but also a slew of similar shoes:
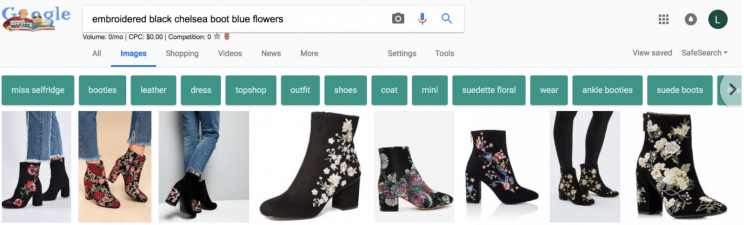
Instead of having to type “embroidered black Chelsea boot blue flowers” and getting a mishmash of results . . .
. . . you can find the items that you’re looking for. This is the best tech we have so far to mimic the way that we process the world around us. If you were trying to find those boots in your closet, you’d never think, “Embroidered black Chelsea boot blue flowers—where are they?” Instead, you’d have an idea of the boot you were looking for, and you’d scan your shoes until you saw a match for the image you were thinking of.
This type of image recognition is the next frontier of digital image search and use. It obviously has implications for commerce, as consumers can simply upload a photo of an item after seeing it in store, on another website, in a magazine, or on a celebrity, and then immediately see options to purchase. It’s also going to have big implications for research and the development of new image-based technologies.
The future is visual
The trend of image search is clear. It’s moving away from text and toward the image. This is in line with what consumers want—nobody is looking for approximations of their searches based on surrounding text. When we have images that we’re working from, it doesn’t make sense to have to translate those into text and then back out again.
From commerce to research to personal use, advanced image recognition is replacing text wherever it can.